

有些正则表达式的不经常用到就会忘记,整理一下,再用到的时候也好便于查询。
零宽度断言
也叫做边界,边界不匹配也不消耗任何字符,只匹配位置。具体的位置有下面几种情况:
一行的开始或者结束,一串字符串的开始或者结束
^匹配一行的开始,$匹配一行的结束。^test.*on$将会匹配第一行,不会匹配第二行,因为这里的正则表达式匹配以test为开头的,on为结束的字符串。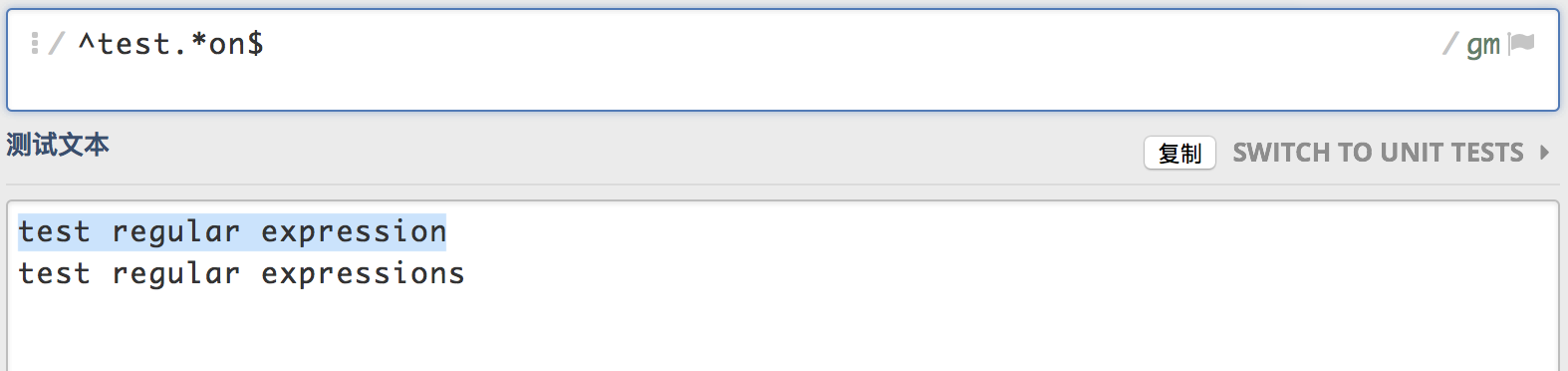
单词的边界,匹配一个单词的二侧
\b匹配一个单词边界,\B匹配一个非单词边界。\bregular\b匹配第一行regular单词二侧的边界,不会匹配第二行regularly,因为后缀ly之后才是这个单词的边界,所以不会匹配。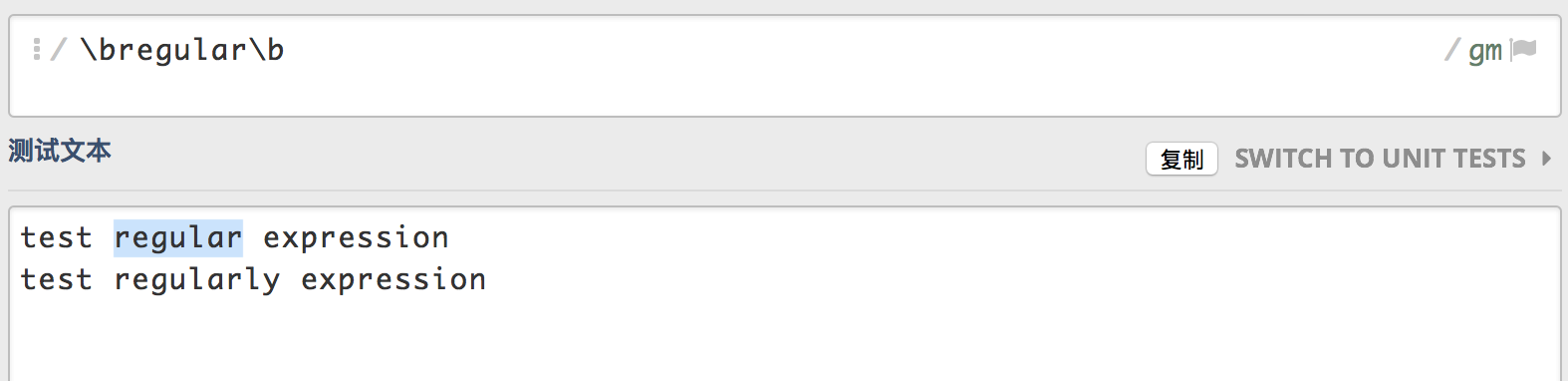
\bregular\B这个表达式意思是regular左边需要是一个单词边界,而右边必须是一个非单词边界,这样就会匹配第二行字符串的regularly的部分字符。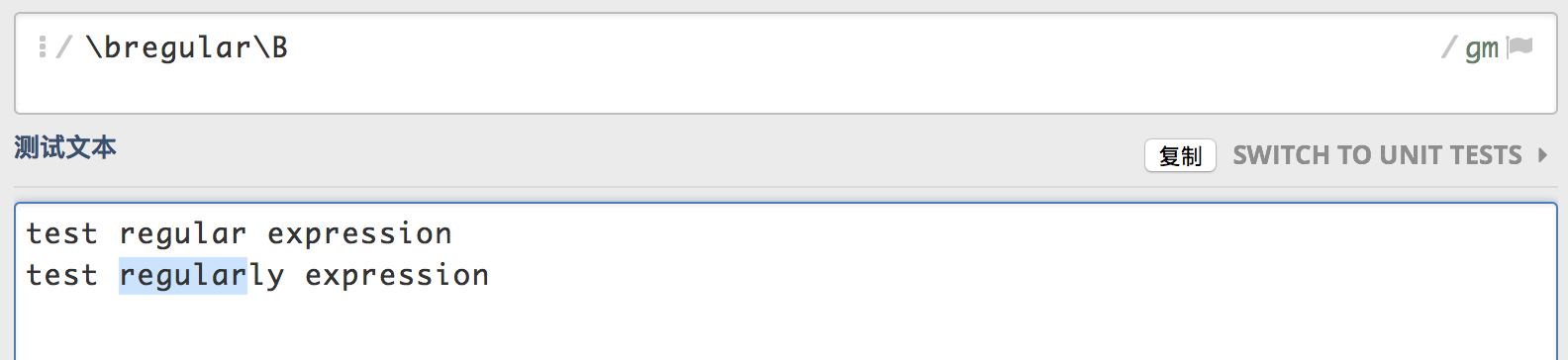
像Vim编辑器里匹配单词边界的符号是
\<和\>,在Vim编辑器我们经常进行查找与替换操作,这个边界匹配就比较有用了,例如,在一大段字符串中想把the这个房间都替换成they,我们会这么敲命令:1
:%s/\<the\>/they/g
这样就能把所有当前buffer中所有the替换为了they,但是如果不加边界修饰,像下面这样写:
1
:%s/the/they/g
这样的确也会把the替换为they,但是类似them这种单词会被替换为theym这样,因为没有边界修饰,the只会匹配所有the这样的字符串,并不是只匹配the这个单词。
字符串字面值限制
\Q和\E之间的所有字符串都会当做普通的字符串字面值来处理,包括正则表达式的元字符也会被直接匹配,不需要特殊的转义。
正常情况如果只有
[]./*||这几个字符,下面什么也不会匹配,因为是一堆元字符。加是\Q与\E之后,[]./*||直接被当做字符串字面量来处理,就可以直接被下面的字符串匹配。
分组
分组捕获
分组使用小括号语法,小括号内的内容即为一个分组。可以使用类似\1,\2,$1,$2,引用不同分组的内容,即从前到后的第几个小括号的内容就是使用
\数字或者$数字的方式进行引用。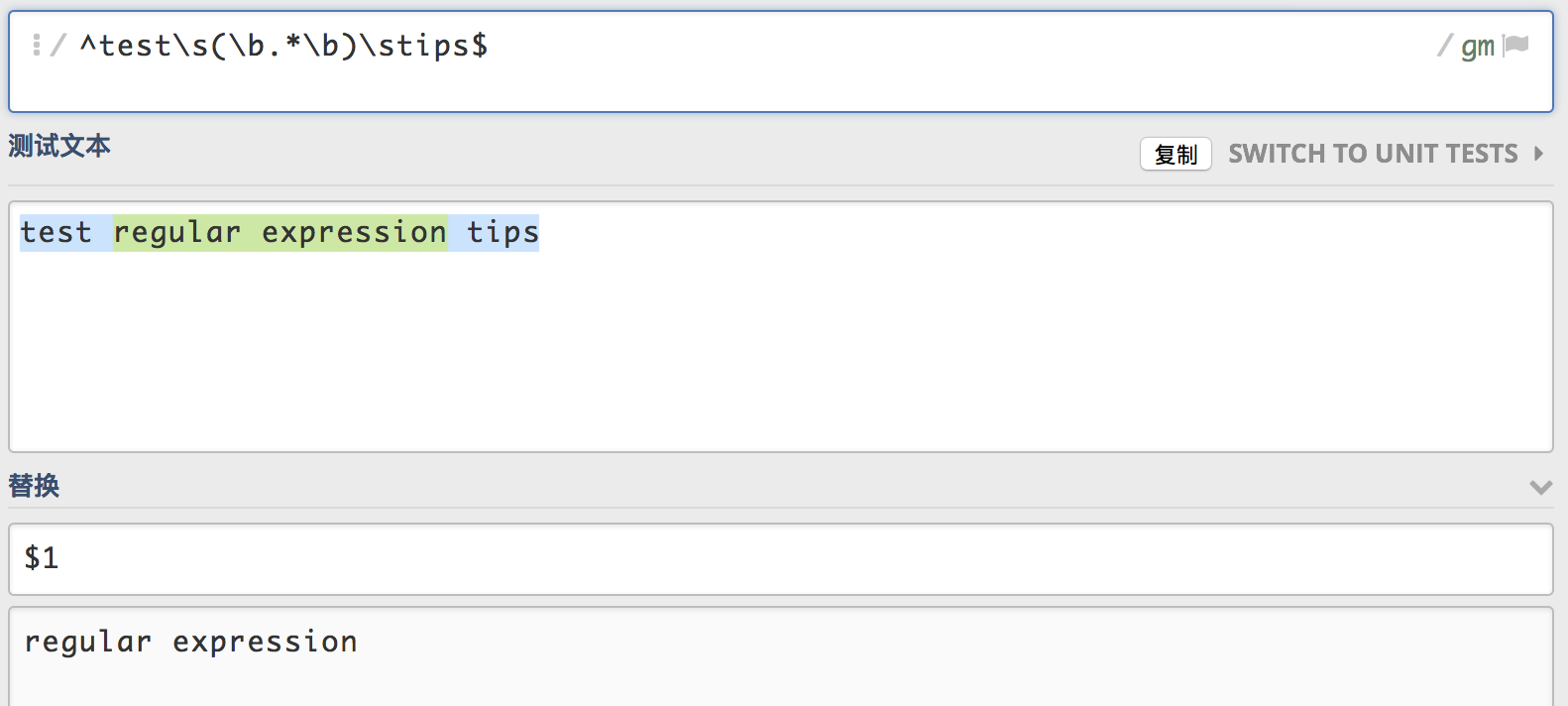
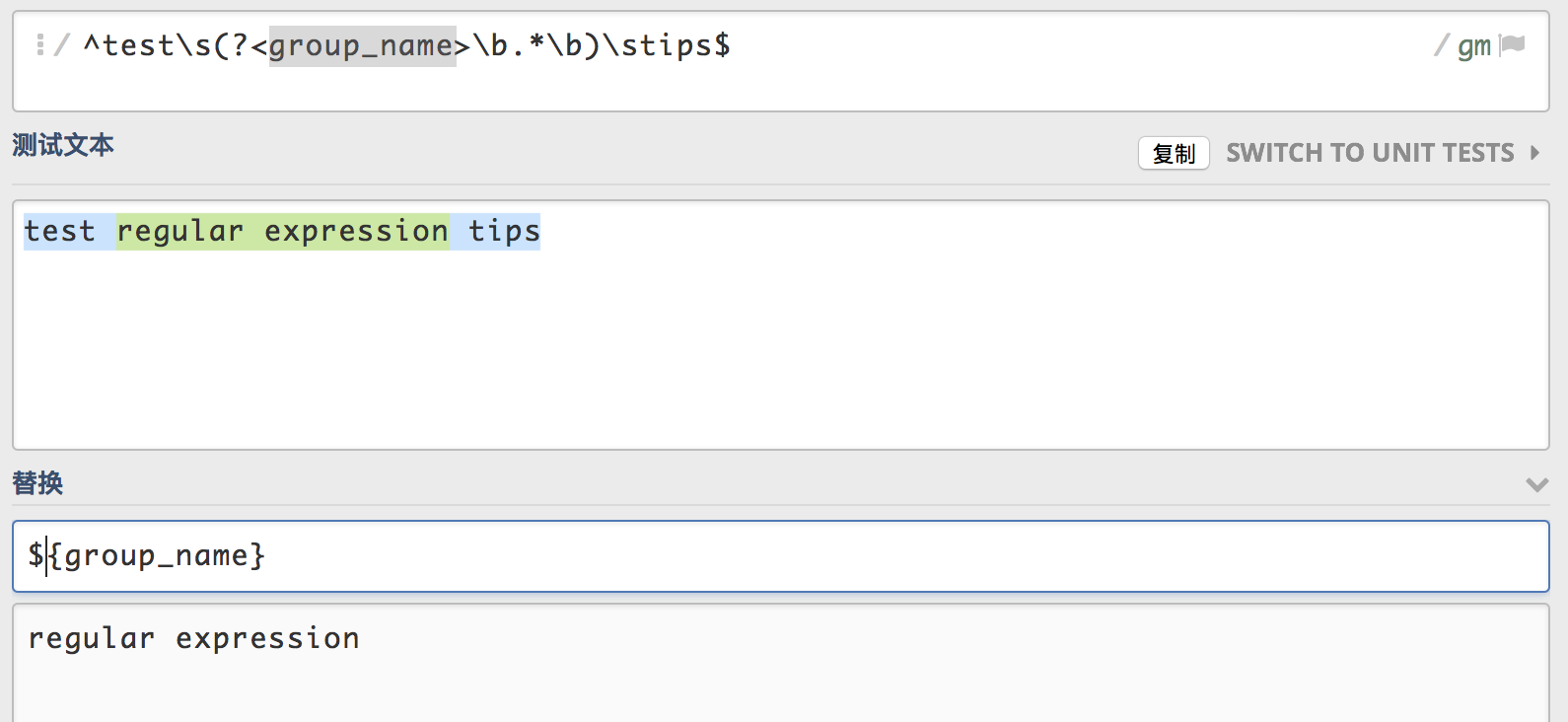
上面的表达式的意思是,test开头tips结尾,test之后与tips之前有一个空格,并且它们之间有一个由任意多个单词组成的分组1,然后使用$1即可引用分组1中的内容。
分组命名
可以不使用默认的数字的引用方式,而直接给分组命名,普通的正则表达式命名如下:
1
(?<group_name>XXX)
?<group_name>这部分是为当前分组进行命令的语法,此部分不参与正则表达式的匹配消耗。引用时使用如下方式:1
${group_name}
即可引用到group_name命名的分组的内容。
不同的语言对正则表达式分组命名与引用方式略有不同,可能不是使用这种普通方式进行命名与分组,具体查看对应语言的文档
非捕获分组
捕获分组并在后面引用是使用小括号,正则表达式引擎这里会把对应的括号里面的匹配内容存储在内存中,以便之后进行引用。如果分组不需要捕获,不需要在后面进行引用,可以使用非捕获分组,这样便不会在内存中存储对应的分组内容,使用非捕获分组的情况就是在非使用小括号不可的情况(通常是限制修饰范围),这样就会造成分组捕获的效果,在内存存储对应小括号的内容,造成性能浪费。非捕获分组语法:
1
(?:XXX)
这样括号中的内容XXX便不会进行内存存储造成性能问题。
字符组操作
字符串取反
1
[^abcd]
在中括号内的^中不是匹配起始位置的意义,而是对后面的字符串进行取反的意思,即匹配的内容不包括^后面的内容。

如上图,意思就是匹配除了r e g u l a r这些字符以外的其他字符。
字符串并差集 (传统普通正则表达式引擎并未实现)
并集
1
[1-2[6-9]] 或者 [1-26-9]
只会匹配 1 2 6 7 8 9
差集
1
[1-9&&[^3-5]]
与上例相同,意思是在1-9数字中,排除中3 4 5这三个数字。
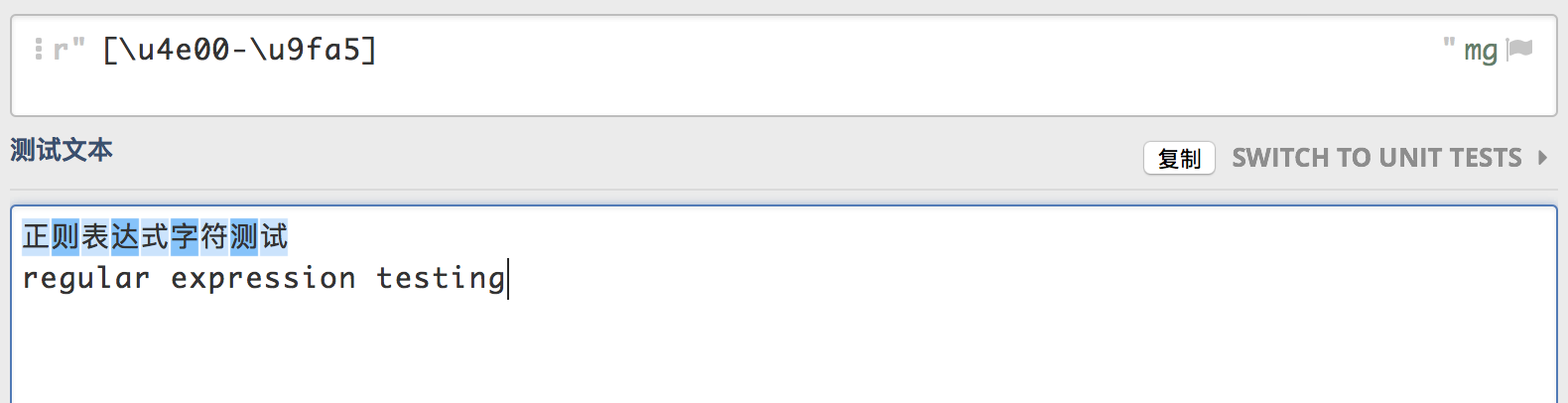
Unicode字符
语法是
\uxxxx,xxxx是对应Unicode字符的十六进制值,此十六进制值不区分大小写,或者使用\xxx的方式,xxx是对应Unicode的八进制值。知道这个就可以根据汉字的Unicode字符范围,匹配所有中文字符。1
[\u4e00-\u9fa5]
匹配量词 贪婪/懒惰模式
量词
使用大括号括起来的数字或者数字区间对前面的模式进行次数控制,语法如下:
匹配特定次数
1
[\u4e00-\u9fa5]{1}
只匹配一个汉字字符,也可以是[\u4e00-\u9fa5]{5} ,匹配5个汉字。
匹配次数区间
1
[\u4e00-\u9fa5]{3,6}
匹配3,4,5,6个汉字。
匹配一个或者多个
1
[\u4e00-\u9fa5]{1,} [\u4e00-\u9fa5]+
加号
+是对前面一种写法的简写,即匹配至少一个汉字。匹配0个或者多个
1
[\u4e00-\u9fa5]{0,} [\u4e00-\u9fa5]*
星号
*是对前面一种写法的简写,即不匹配或者匹配多个汉字。匹配0次或者1次
1
[\u4e00-\u9fa5]{0,1} [\u4e00-\u9fa5]?
问号
?是对前面一种写法的简写,即不匹配或者匹配一个汉字。匹配n次或者更多次
1
[\u4e00-\u9fa5]{4,}
匹配至少匹配四个或者更多汉字。
贪婪模式
在对应量词后面加上再加一个加号
+,贪婪模式即,按当前匹配量词尽可能多的进行匹配。懒惰模式
在对应量词后面加上再加一个问号
?,懒惰模式即,按当前匹配量词尽可能少的进行匹配。
环视
环视匹配位置,也是不消耗任何字符。
正前瞻
1
pattern(?=p)
pattern 后面需要紧跟p,才能匹配。
反前瞻
1
pattern(?!p)
pattern后面不能跟着p,才可以匹配,其实就是正前瞻的反操作。
正后顾
1
(?<=p)pattern
pattern前需要有挨着p,这样能匹配。
反后顾
1
(?!=p)pattern
需要pattern前面不能是p才能匹配
使用环视给数字添加分隔符, 如12345, 处理成12,345这种
1
2
3
4
5
6
7
8
9
10#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
number = "12345678"
pattern = r'(?<=\d)(?=(\d{3})+$)'
num = re.sub(pattern, ",", number)
print "original number: ", number, " replaced number:", num(?<=\d)(?=(\d{3})+$)匹配的是左边是数字,右边是三位数字结尾的一个位置,在这个位置插入一个逗号,由于这只是一个位置,不消耗具体字符,所有原数字不在替换范围之内,只会在正确的位置插入逗号。